Last year I started using Obsidian in combination with some other tools to help with knowledge management. It’s quite common that I attempt to visit a web page to find the original content no longer exists, either as a result of the usual link-rot where websites die or get restructured, oreven due to wilful destruction of content in the case of many reddit pages, or nuking old content and domains as a result of company buy-out.
This year, I’ve decided to complement my personal management system by deploying ArchiveBox to save content that I might want to read again in future. ArchiveBox is a self-hosted internet archive solution, that functions in a similar way to archive.org.
Why self-host an archive?
Why would I need to self-host a solution when the wayback machine at archive.org functions as a useful archive of the whole web? Well, ArchiveBox not only preserves valuable content, but is also useful search engine for pages that I’ve saved. It’s quite common that I cannot recall exactly where I read something, and end up spending quite a while searching for it again from scratch on Google/search engine of choice, looking for links I’ve visited in the results. Good bookmark management cannot provide the exact website I need in this scenario. I often save websites to Pocket too, but disappointingly, this doesn’t allow text search - it is essentially just a bookmarking service -and there seems to be no sign of Mozilla open-sourcing the Pocket server code yet.
So, my main reasons to self-host an archive
- archive.org is painfully slow, archivebox running on my LAN is fast
- I want to limit searches to only content that I’ve elected to save
- the pages I might want to see aren’t necessarily archived at archive.org (this could be easily remedied with a Firefox add-on)
- you can tag links in ArchiveBox, creating a useful knowledge base
- offline access - a repository I could use if I, or archive.org is offline is potentially useful
ArchiveBox features
ArchiveBox has a user-friendly UI, accessible via a web browser, plus fully featured command-line options, and an API is under current development. The web interface is clean and easy to use, and allows me to navigate my saved articles and read them in various formats, add tags to articles and filter by tag and/or date range, and perform a text search on the whole archive, which is going to prove very useful for me as a searchable knowledge base to complement the notes I make in Obsidian. I’m more likely to archive a bunch of sites and then write notes using this content afterwards, but it’s also going to prove very useful for things like doing market research - as someone who hires frequently, I often manually save PDFs of related job adverts in my sector, which typically get deleted as soon as the advertising window is closed. The UI also offers the option to take a new snapshot with the Re-Snapshot button.

Performing a text search on the archived content
Regarding search, the default is to use ripgrep on the backend to search the archive, which has been sufficient for me so far. There is also the option to use the Sonic search backend, which offers fuzzy text searching, but the documentation doesn’t explain enough for me to understand the difference, usage or benefits. There is an issue outstanding to improve the docs for the features offered by Sonic.
Archive methods
By default, ArchiveBox will save a copy of the required website using a variety of archival methods, such as cloning with wget or using chrome headless mode to produce PDF, screenshot and singlefile archives. It will also automatically submit the site to archive.org (which I disabled due to personal preference), and will archive audio and video files using youtube-dl.
It’s a good idea to leave most of these methods enabled, since although the wget clone method is usually reliable, it sometimes doesn’t produce the desired results, while Chrome->Singlefile snapshots don’t allow replay of javascript, so you can’t minimise a banner that might be obscuring a page. The PDF results are usually very good, and there is also a text-only readability mode. One of these methods will provide the full article cleanly, even if another method fails for some reason.
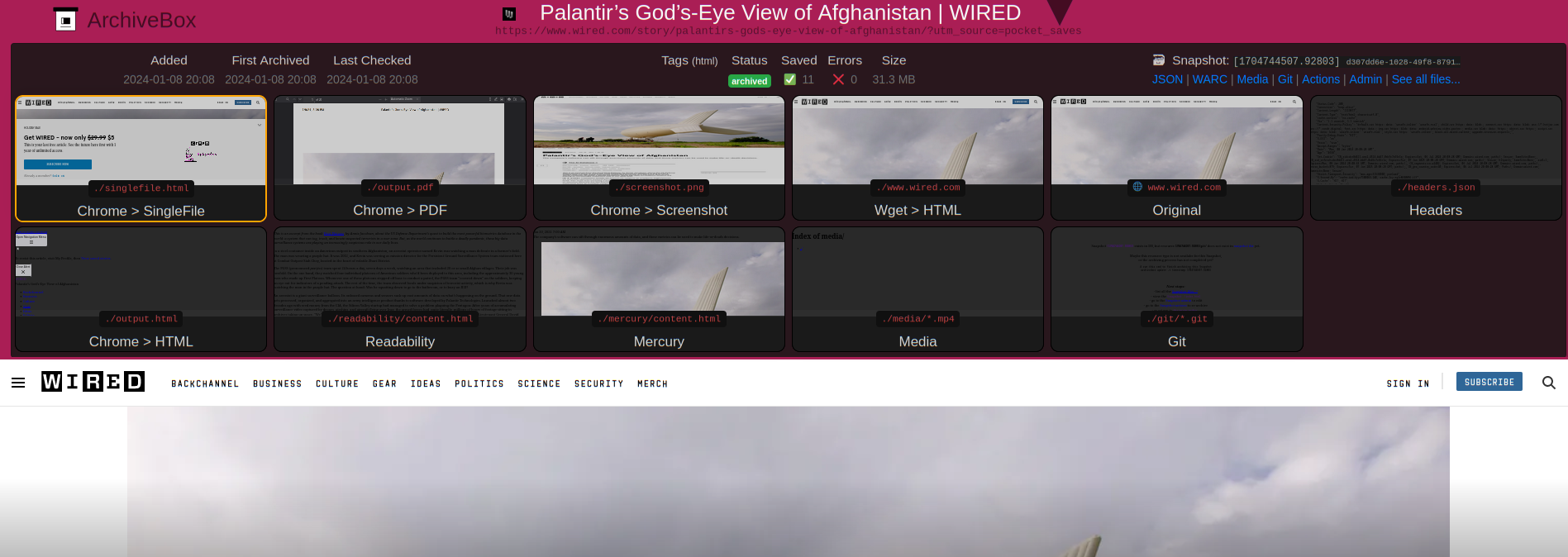
Inspecting an archived article. The top banner showing the different archive methods is collapsible
ArchiveBox deployment
I recently acquired a Wyse 5070 Thin Client PC for less than the price of a Raspberry Pi. It sips power and is completely silent. I replaced the existing M.2 SATA drive with a larger one, installed Ubuntu MATE 22.04, and deployed ArchiveBox using Docker, which had a well documented install procedure. I’m not a massive fan of Docker, but it seems like a good solution for this type of application, since there are a lot of dependencies would otherwise need keeping updated.
I have pi-hole on my network already, which reduces the ads, but there is a documented method of spinning up pi-hole docker instance to funnel requests through, in order to clean up archived content.
I had to add an alias archivebox='docker compose run archivebox' to simplify running various CLI administration tasks (e.g. running archivebox config --get to see the current configuration state).
Although there are some useful command-line options, most users will interact via the user-friendly web UI which starts on port 8000 by default, as it’s recommended to run as a non-root user. It’s possible to spin up an nginx container using docker to server this on more standard ports.
Deduplication
ArchiveBox stores data in a user-friendly way, and it’s easy to inspect the content from the command-line. I soon realised that quite a lot of files were being duplicated (e.g a directory full of fontawesome fonts consumed 14MB, and appeared 5 times already on my small but growing archive. Not only fonts, but there’s quite a lot of overlap in the assets used by 2 articles archived from the same website. Although ZFS does block-level deduplication, it appears to be discouraged, certainly on lower powered systems. However rdfind does exactly what I need, in that it finds identical files and creates a hardlink instead, meaning that I can delete either copy of a file in future without breaking anything. On the first run of rdfind, I reduced the data capacity of my archive by over 30%. I added the following cron job to remove duplicates on a nightly basis:
0 22 * * * rdfind -makehardlinks true -outputname rdfind.log /home/archivebox/data/archive
Adding sites to the archive
You can snapshot a site, or list of sites via the command-line or web UI. You can import browser history, bookmarks, pocket, wallabag, etc. You can even schedule regular imports from RSS feeds.
However, adding a site manually is a bit jarring - I want to seamlessly send sites to the archive as I browse. This extension adds an option to the right-click context menu while allows me to send the current web page to the archive.
Issues and quirks
All in all, I really like this project. If you heard of it a few years ago, you might want to take another look as there’s been a lot of improvements since. One feature I would love to see implemented is the ability to run user-scripts or extensions before the chrome export takes place. Quite a few export methods produce pages which are covered in cookie consent banners, and the ability to run something like “I still don’t care about cookies” when the snapshot takes place is desperately needed (Chrome headless mode doesn’t work with extensions). I’ve seen some issues mentioning Cloudflare, but I haven’t come across them yet. Another issue is that I sometimes send a site to my archive but don’t realise that it requires authentication (such as a knowledge-base article behind a login-wall). It’s possible copy a chrome profile (containing a bunch of cookies) to the ArchiveBox server, and I have played a bit with this, but at one point I experienced an issue where new sites stopped getting archived because of a Chrome error saying the profile was already in use elsewhere. I’m not sure whether this is easily fixable but for the moment I’ve stopped using a custom Chrome profile with ArchiveBox.