…also known as “Solving the Working from Home bandwidth problem”. A common
task I perform as part of my job is to download large files from websites onto
a server. Often my aim is to download such files directly onto the Linux servers
residing in the datacentre, and most of the time this is straight-forward: open
an ssh connection to the server, and pass the url to the wget command. The
file is promptly downloaded directly to the server at several Gigabits per second.
However, occasionally (for example, downloading 300MB of CUDNN libraries from
NVIDIA, or downloading large machine learning datasets), I am required to first
authenticate in a web browser before I am able to download these files. If I
then try passing the download URL to wget on a remote server, I’m likely to
be denied permission, since I don’t have the session cookies on the server to
track my authenticated session.
When working at the office, I usually get around this annoyance by first using the browser to download the files to a temporary folder on my desktop PC, and then subsequently upload the files to the destination server. It’s not ideal, as it’s a 2-step process that needs my attention for each stage, but since I have a high bandwidth connection to both my PC and the server, it’s quite a quick process, unless I’m downloading a very large file or I get otherwise distracted and forget to complete the task.
However, I’ve spent the last 4 months working from home, and while my ADSL bandwidth is sufficient for video calls and streaming TV, downloading and subsequently uploading a couple of 300MB+ files over my ADSL connection introduces an unnecessary hour-long bottleneck into the workflow, particularly due to my relatively slow upload speeds. This really forces the issue of finding a more direct method of downloading the type of files that are only downloadable via an authenticated session.
The challenge we have is to log in with the browser, locate the desired file to download, capture the browser session information and continue the download on a remote server. Turns out, it’s not so hard.
Within Firefox, open the Network section of the Developer tools with Ctrl-Shift-E. If using Google Chrome, hit Ctrl-Shift-I and choose the Network tab if it’s not already selected.
Then click the item you want to download. The Save/Open browser dialog appears, and the download request will appear as 2 rows in the network monitor. At this point we can grab the session information without actually proceeding with the download in the browser. Right-click the longer URL that shows the session information as part of the filename. You can then either choose Copy->Copy URL or Copy->Copy as cURL. You can then cancel the download request.
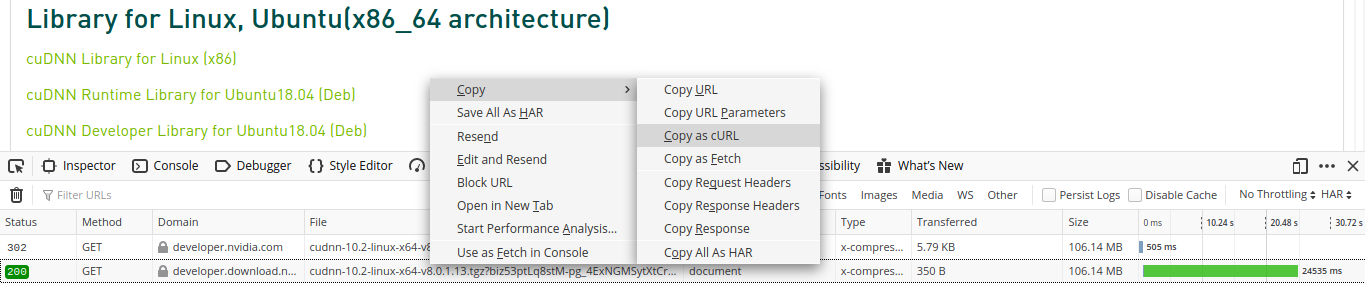
Grabbing the curl data for a download from an authenticated session
If you choose Copy as cURL, the whole curl command is now copied to your
clipboard. Paste it in a terminal on the remote server, add add -o
filename.tgz or a redirect > filename.tgz to save the contents as a file.

Using the session data to download on a remote server
If you choose to copy as a URL, you need to type wget before pasting your
clipboard contents, and you will probably want to name the file with -O
option, e.g. wget <url from clipboard> -O filename.tgz
There are also other ways around this problem. You could export cookie files and pass them to wget/curl. In the past, there have been browser extensions which functioned with varying degrees of success. There may be other more fiddly solutions for a fully CLI workflow if you want to automate or repeat the same task regularly. However, for the occasional requirement where you want to initially want to login and locate the file within a browser, this ad-hoc workaround of getting the browser to do most of the work for you, is easy to remember and seems to work with minimum of fuss.